7 min
Drei Bühnen in zwei Wochen -- als Builder, nicht als Speaker
waff Future Fit Festival, web3 hub vienna und Wien Software Architecture Meetup: drei Auftritte hintereinander. Warum ich auf Bühnen gehe, weil ich baue – nicht umgekehrt.
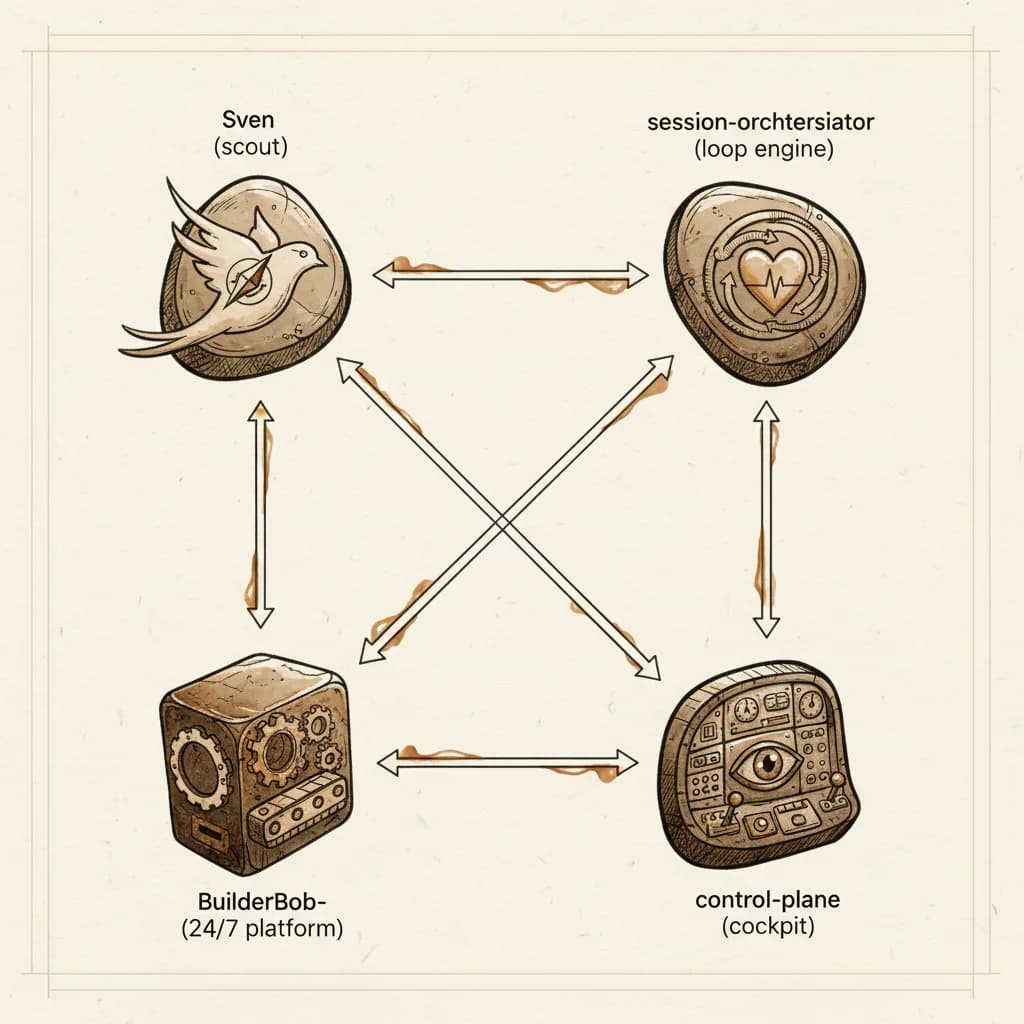
Behind the Scenes